What it is
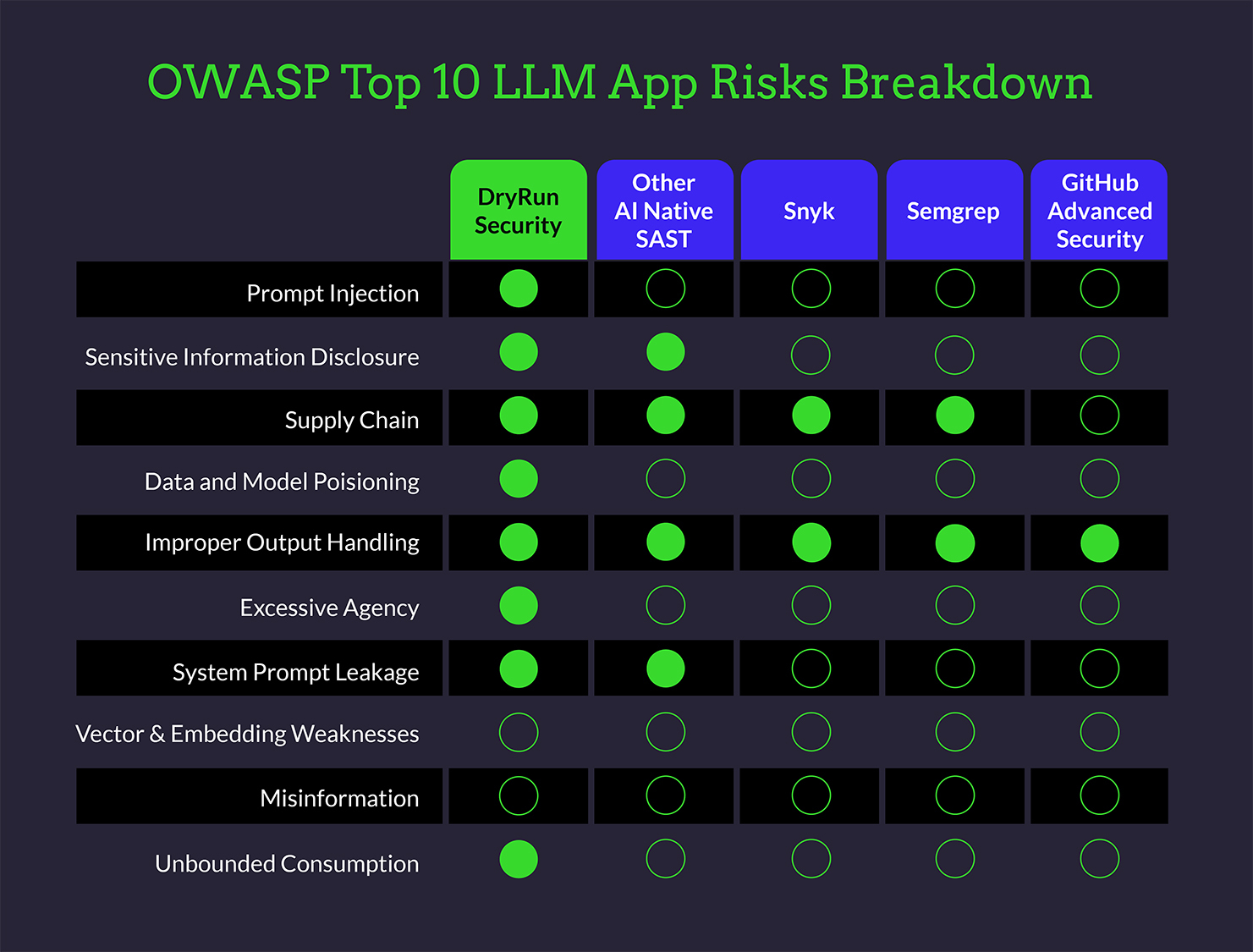
Excessive Agency is the risk that an LLM system is given too much power to act such that unexpected, ambiguous, or manipulated model outputs lead to real operations that you never intended. OWASP defines this as harmful actions triggered by the model’s behavior, regardless of whether the root cause is a jailbreak, prompt injection, weak tooling, or simply a poorly performing model. In practice that looks like agents calling write APIs, moving money, changing records, or touching production systems without the guardrails that normal software would face.
Why leaders care
Once a model can act, jailbreaks and indirect injections stop being a theoretical nuisance and become a path to operations. Benchmarks such as InjecAgent show that tool‑using agents remain vulnerable to indirect prompt injection embedded in web pages, documents, or emails. In some ReAct patterns the attack success rate was measurable, which is enough to justify engineering controls before you put agents near sensitive tools.
Stronger safeguards are not a silver bullet. The UK AI Safety Institute and independent labs have published results showing that modern models’ protections can be bypassed, including many‑shot jailbreak techniques that work better as context windows grow. If an agent can spend money, send data, or reconfigure systems, assume safety filters will sometimes fail and make sure nothing catastrophic happens when they do.
Real programs have already learned the hard lessons of automation at the edge. McDonald’s ended a multiyear AI voice ordering pilot after a run of high‑profile order errors, then signaled it will reassess approaches. Even though a drive‑through is not your finance API, the governance lesson is the same: agency without tight controls quickly becomes customer‑visible risk.
What controls are needed
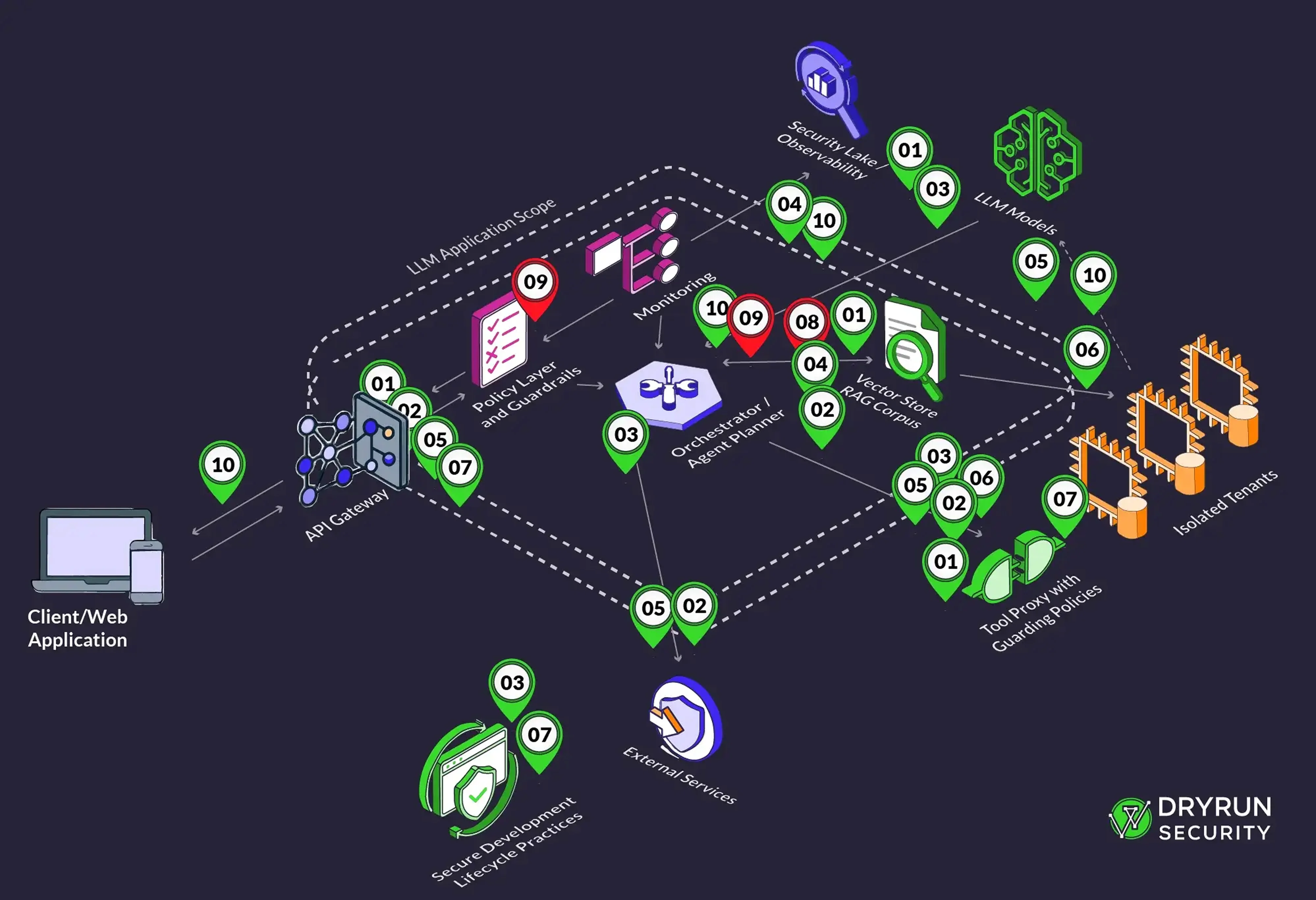
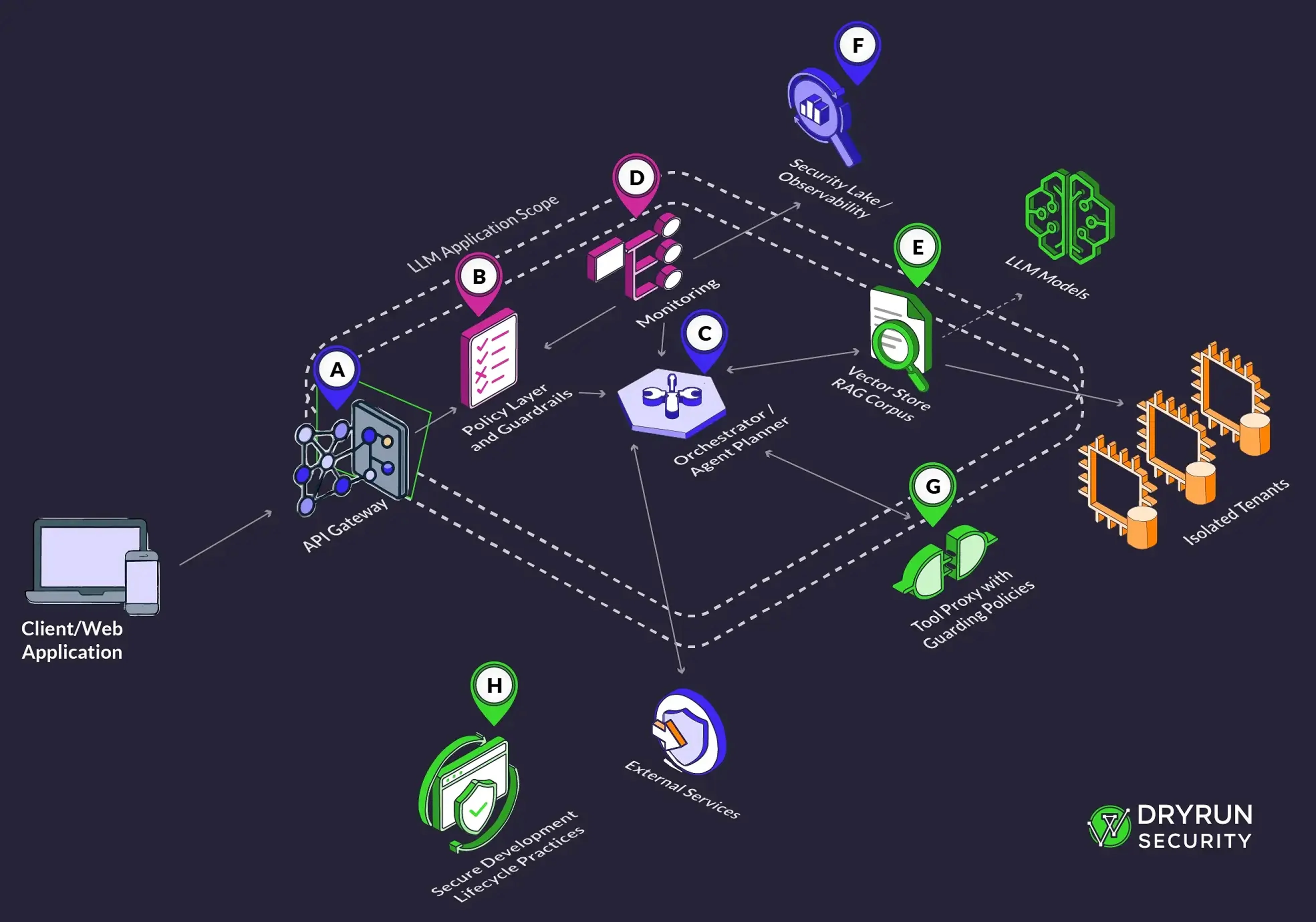
Define hard boundaries around action
Give agents the fewest tools possible, each with least‑privilege credentials, time‑boxed tokens, and explicit allowlists for operations and destinations. Put a tool proxy in front of every action surface that validates JSON Schema for arguments, blocks default egress, and forces human approval for anything destructive or financial. Modern cloud services let you associate guardrails with agents and tune prompt‑attack filters, which is useful as a first line of defense but should not replace your own allow‑deny logic.
Mediate tool calls in policy, not in prompts
Place a policy layer between the model and tools that enforces contracts before an action is even attempted. Use execution‑time hooks that can veto or transform tool calls, and keep those hooks versioned and testable. Open tool frameworks document “execution rails” that trigger before and after an action, which is exactly where you enforce allowlists, rate limits, and approvals. If you expose a “computer use” or RPA‑style capability, run it inside a sandboxed environment per vendor guidance.
Instrument and continuously test
Log every tool invocation with inputs, outputs, identity, and approvals. Alert on unusual sequences, long loops, or calls to unapproved hosts. Add agent‑specific red‑team tests alongside your CI that try indirect injections and unsafe tool chains so regressions are caught before release. Community benchmarks such as InjecAgent and Agent Security Bench are useful seeds for the test suite. Treat failures as product bugs and tighten policies, schemas, and approvals accordingly.
Tools to consider
Policy and Governance | Knostic Prompt Gateway
A policy and governance layer for copilots and agents, with inspection, sanitization, approvals, and egress controls for tool calls. Knostic won Black Hat’s 2024 Startup Spotlight, which is a useful signal of problem relevance for agent security.
https://www.knostic.ai/
Guardrails | NVIDIA NeMo Guardrails (open source)
Programmable guardrails that sit between your app and the model with “execution rails” to intercept and control actions. Use it to keep policy outside the prompt and to enforce allowlists and schemas before and after tool invocation.
https://developer.nvidia.com/nemo-guardrails
Policy and Guardrails | DryRun Security
AI‑native code analysis that flags places where agents render or act on model outputs without schema checks, sandboxing, or approvals. Useful for catching missing guardrails in code before runtime, as well as picking up poor authorization controls across tool calls.
https://www.dryrun.security









.webp)
.webp)
.webp)
.webp)