Ok, first, let’s be honest.
Most security conversations about Git history are painfully predictable... Someone committed a password. Someone left an API key in an old branch. Someone pushed a secret, rotated it, and then when the team is upset, they had to explain to the team why “it’s deleted now” isn’t actually how Git works.
That stuff matters, of course. But it’s also the obvious part in the year of 2026.
What has surprised me over the last few years building DryRun Security is that Git history has become one of the richest sources of security intelligence inside a modern software company, and not for any of the reasons most people think. The value isn’t that it tells you what the code says. The value is that it captures code-change behavior over time, how teams interact with the codebase, and how the system actually evolved, rather than how it was originally designed.
A static call graph can show you which function calls another function. Dependency analysis can show you which package imports another package. Architecture diagrams can show you how the system was supposed to be designed (assuming they were ever accurate and somebody remembered to update them sometime in the last five years). Git history is different because it captures historical movement.
One of the most interesting examples of this relevance to contextual security analysis is temporal coupling.
Temporal coupling occurs when two or more files are modified within the same time window frequently enough to not be considered correlated.
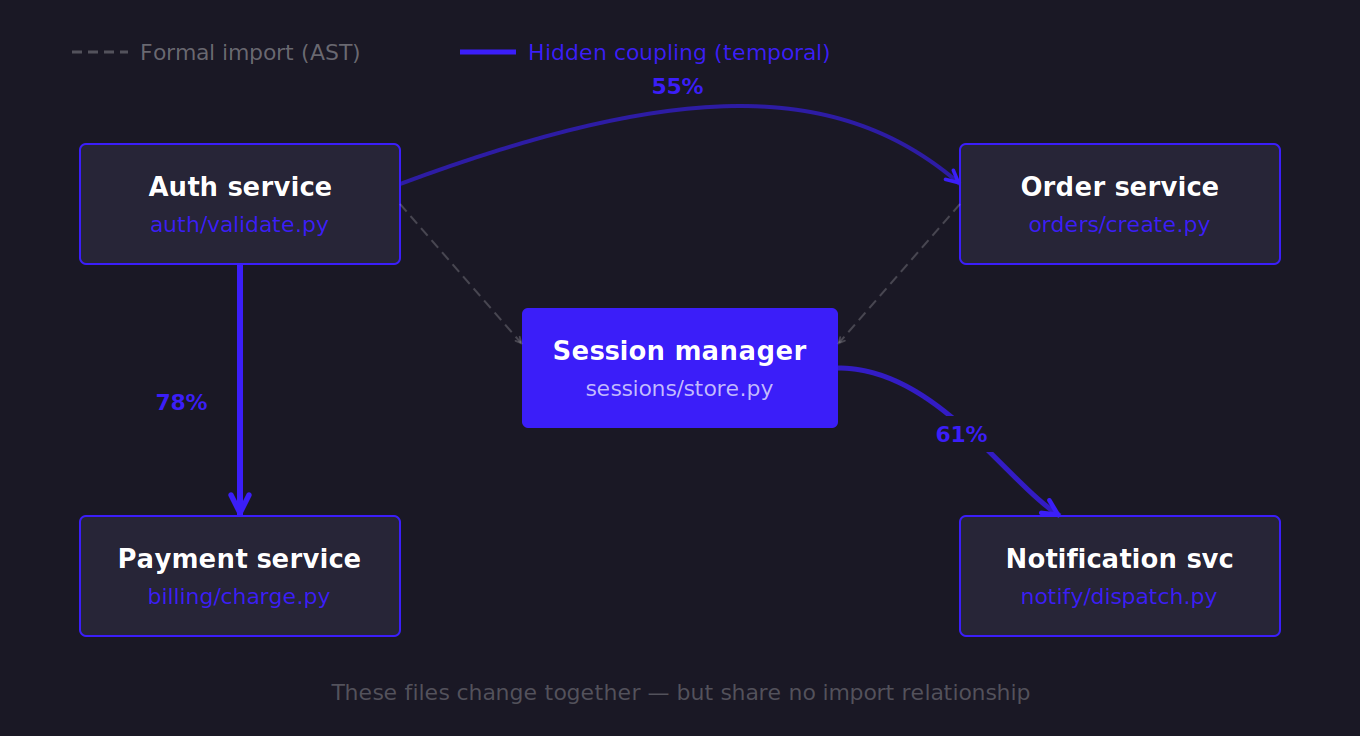
In a microservices environment, some of the most important relationships are completely invisible when you look at the code statically. A payment service and an authorization service may never directly import each other and therefore never appear connected in a call graph. A feature flag system and a customer entitlement workflow may live in completely different parts of a mono-repo and be undocumented. A Kubernetes configuration, an API route, and a session validation module may exist in separate repositories, each managed by a separate team. If you looked at the system through the lens of structure alone, you could reasonably conclude that these things have very little to do with one another.
But the history in your source control management tools (e.g., GitHub Enterprise, GitLab) contain the truth.
Over months and years of development, patterns start to emerge as files get changed together. When two files, services, or repositories repeatedly change during the same window of work, there is usually a reason. Sometimes that relationship is obvious, but more often it isn’t. It may represent an undocumented dependency, an operational workaround that became permanent, a business process that evolved organically, or a security boundary that exists only in the heads of a few engineers who happen to understand how everything fits together.
What makes this particularly interesting from a security perspective is that many of the highest-impact vulnerabilities are not isolated to a single file, function, or service. Authorization flaws, tenant isolation issues, and business logic vulnerabilities often arise from interactions among multiple systems. Understanding those relationships turns out to be just as important as understanding the code itself, and those relationships are often much easier to discover by studying how software changes than by studying how software is structured.
This is one of the reasons we’ve become so interested in Git behavioral graphs at DryRun Security, because it helps us understand where risk is most likely to live before we ever begin analyzing code. If we can identify the parts of a system that are unusually interconnected outside of a call graph, we’ve already learned something useful about where deeper investigation should begin.
This is where I think many security tools struggle. Most tools evaluate code exactly as it exists today and attempt to determine whether a pattern is dangerous. That’s useful, but it ignores the history that produced the system in the first place. Security risk isn’t just a property of code. It’s also a property of change, ownership, institutional knowledge, and system evolution. The path a system took to arrive at its current state often tells you as much about future risk as the code itself.
Giving an AI an entire enterprise codebase and asking it to find problems is a bit like dropping a security engineer into a Fortune 500 company and saying, “Good luck.” The best reviewers don’t start everywhere. They start in the places where experience tells them risk is most likely to be hiding. They look for unusual patterns, hidden dependencies, and signs that a system has drifted away from its original assumptions. I
That’s ultimately what we’re trying to do at DryRun. We’re teaching our AI system to start where experienced security engineers would start. The goal isn’t simply to generate more findings. It’s to develop a better understanding of where risk actually lives inside a modern software system so that analysis can be focused where it matters most.
If that sounds cool to you, that's the tip of the iceberg on the new approaches we're taking at DryRun Security, and our team would love to help you get contextual security analysis helping your organization.


