When we first started experimenting with what would eventually become our Custom Policy Agent, the idea sounded deceptively simple:
What if you could ask a question about a pull request in plain English, something like “Does this change modify authentication logic?” and get an accurate answer?
At the time, we called them Behavioral Questions. They were defined in YAML, took a question and a bit of code context, and ran against pull requests. It was an early prototype of what we now call Natural Language Code Policies and it was both exciting and wildly unstable. We even secured a spot as Black Hat Startup Finalists 2024 for this invention!
The Early Days: Simple Idea, Hard Problems
Those first iterations worked… sometimes. But we quickly ran into the kind of challenges that make or break a system like this.
- Repeatability: The same question asked twice could produce slightly different answers.
- Accuracy: Results drifted depending on the complexity of the code or question being asked.
- Review Planning: Analysis runs were messy, with early AI-driven coordination and little human oversight.
- Speed: Queueing and execution bottlenecks were not terrible but needed to be much faster.
- Limited Context: The system only saw code inside the PR. That meant it missed dependencies, helper functions, or related logic outside the diff.
It was enough to prove the concept, but not enough to scale. We needed a foundation that could deliver consistent, high-fidelity results across any repo, language, or environment.
Evolution: From Behavioral Questions to Natural Language Code Policies
The next phase was a big leap. We rebuilt Behavioral Questions as Natural Language Code Policies (NLCPs) and moved the whole experience into our dashboard.
That shift mattered because it gave users real control instead of a YAML file they had to maintain. Policies were now much more capable and intuitive, including:
- Rich background context: Why this check matters, what files and folders to exclude, good and bad examples, documentation, and anything else that helps inform the analysis.
- Custom remediation guidance: The ability for policy builders to place their organization’s specific mitigation strategy as guidance when the issue is flagged in a code change.
- Policy Dashboard: A visual interface for building, testing, and managing NLCPs all in one place.
We also rebuilt the evaluation layer from the ground up to ensure accuracy and repeatability. Under the hood, we focused heavily on orchestration: better queueing, improved notifications, and streamlined concurrency so that policies ran faster and more predictably.
Confidence Through Testing: The Policy Builder
Once NLCPs lived in the dashboard, we wanted users to trust them before deployment.
So we built the Policy Builder, a place to point policies at specific repos and pull requests to see how they behaved in real conditions.
It let users verify that:
- The policy is working as intended
- The results are consistent
- Execution is fast enough for production use
This was one of those simple-but-critical steps that turned experimentation into adoption across our user base.
The Agent Era: Expanding Context and Intelligence
Even with all that progress, one limitation kept surfacing. Sometimes, the PR itself wasn’t enough. Developers and security reviewers often need broader code context to understand what a change means in the larger system.
That’s when we introduced our first agent, a component capable of fetching relevant code from the wider repository for ephemeral analysis.
It gave each policy deeper insight into how a change fit into the surrounding codebase.
From there, we kept expanding:
- A Just-in-time research agent that could look up information about frameworks, languages, or vulnerabilities from approved documentation and allow-listed websites.
- An SCA agent that checks for Common Vulnerabilities and Exposures (CVEs) tied to dependencies.
- A license agent that validates open-source license compliance.
Each agent added more depth, accuracy, and autonomy to our analyses. Together, they turned NLCPs into something much smarter than a static rules engine.
We Thought Natural Language Was Enough. We Were Wrong.
Our next lesson was a human one.
We assumed that using natural language meant people could easily write their own policies. It turns out… not really.
Everyone writes questions differently. Some are verbose, some vague, and some mix intent with background story. LLMs can handle a lot, but ambiguity still creates drift.
So we built an AI-powered Policy Assistant to help.
It walks users through creating policies by asking precise, context-specific questions and clarifying what they want to detect, what context matters, and what feedback should be shown to developers.
By the end of the conversation, the user has a ready-to-run, testable policy that’s been engineered for accuracy and clarity.
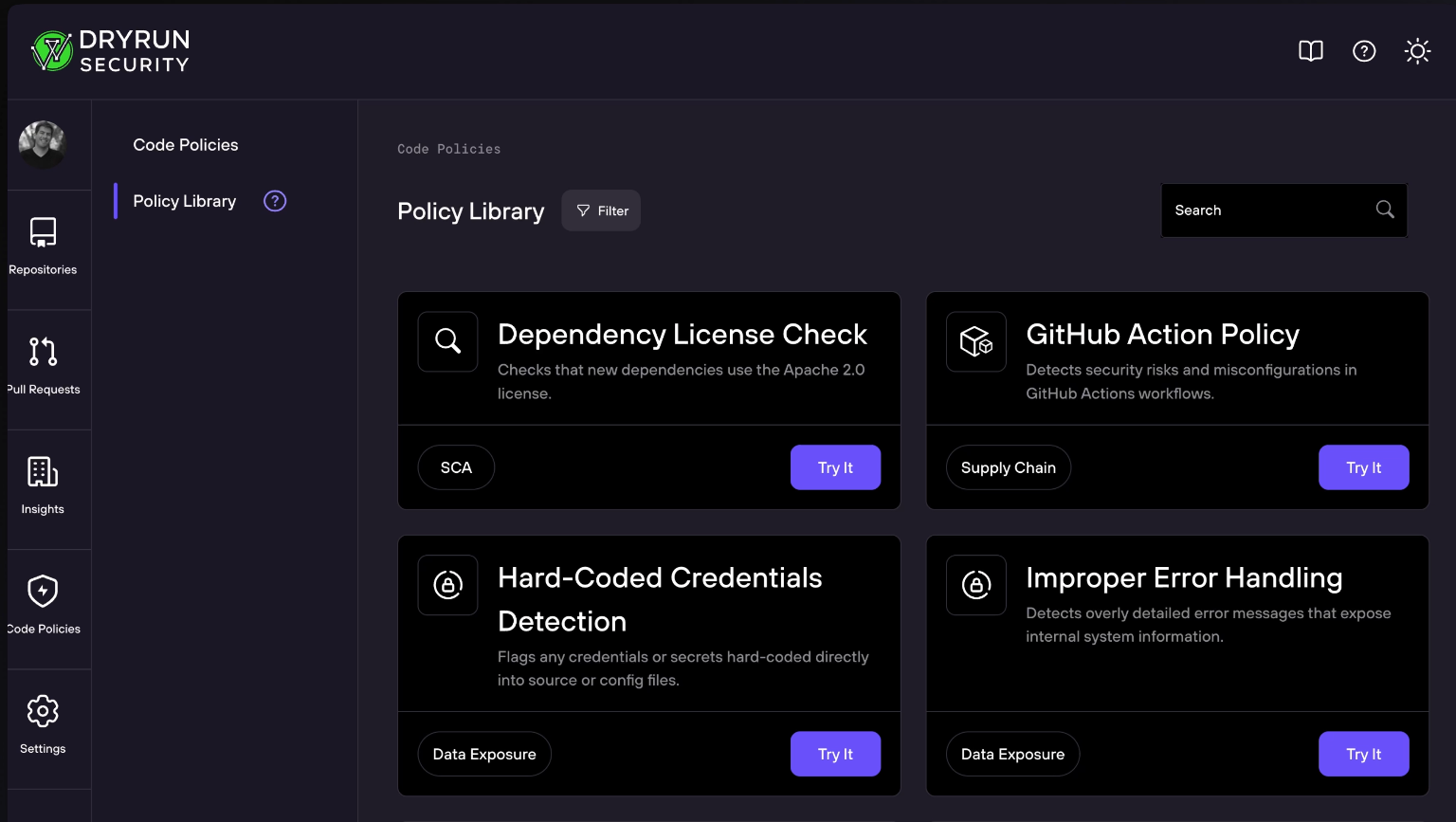
Collaboration and Creativity: The Policy Library
As our customer base grew, we started seeing patterns and different teams solving those same kinds of problems in similar ways.
That insight led to the Policy Library, where users can use or customize policies depending on their goals and coding environment.
It’s a set of shared policies where security and engineering teams can pick from this list of pre-built policies and immediately begin to experiment, iterate, and learn from each other in a community-driven layer built right into the product.
Custom Policy Agent: Where We Are Now
At this point, the term “NLCP” no longer fits all that we’re doing for policies. It’s no longer just natural-language prompts.
It’s autonomous, a Custom Policy Agent that calls sub-agents on demand. Adaptive, autonomous systems driven by your policy and capable of reaching beyond the code in the PR to reason about behavior and intent across any technology stack.
Our latest iteration introduced something we’re especially proud of:
Larger agents create execution plans for smaller, focused sub-agents, which means reviews are faster and more precise.
Each analysis involves reasoning, strategy, and decision-making and it is all orchestrated in seconds. The smaller agents handle targeted inspection and coordination, while the larger ones perform deep inspection and synthesis. The result is faster, more accurate, and more consistent analysis than ever before.
Looking Back, and Ahead
Competitors are now developing their own early, incomplete versions of this system, which we see as a significant compliment and a strong validation of our approach to the problem.
It just makes sense.
Why spend time writing brittle rules for each stack, that can only match surface-level patterns, when you can speak to a system in plain language, detect complex logic and authorization issues, and apply it anywhere?
That’s what our Custom Policy Agent delivers.
It started as a YAML file and a question.
Now, it is an intelligent, adaptive, agentic layer that helps AppSec teams reason about code the way developers do, in context.

.jpg)
